Quando falamos sobre data analytics é comum associar modelos baseados em algoritmos, machine learning e até lembrar de ferramentas de BI com grandes painéis de controle, cheios de informações. Hoje vamos explicar uma parte fundamental desse processo, que acontece ali nos bastidores: o data transformation ou transformação dos dados.
Essa etapa é importante porque raramente um dataset atende 100% das necessidades de quem está usando ele. Durante o processo de transformação dos dados, os conjuntos de informações são lapidadas para que revelem informações úteis.
Um exemplo que torna o conceito mais fácil de entender: imagine que você precisa analisar o resultado de performance de um anúncio em rede social. Ao visualizar os dados brutos, porém, é possível perceber que existem algumas células quebradas ou valores que estão ausentes ou até incorretos.
Ou seja, antes de jogar esse material para um software de visualização e garantir sua precisão, é preciso “lapidar” esse dados brutos. Essa etapa da gestão de dados é chamada de data transformation ou transformação de dados.
Saiba mais sobre data transformation e os principais métodos para essa técnica.
O que é Data Transformation?
Data transformation ou transformação de dados é o processo de mudança de dados de um formato para outro. Esse conceito é uma parte crucial para qualquer pipeline de dados — e precisa vir antes da chamada análise de dados ou data analytics. Para que os dados possam ter mais impacto, é necessário que sejam precisos e também que sejam compreensíveis.
Alguns exemplos de mudanças que podem ser realizadas nos dados durante a data transformation são: mesclar, agregar, resumir, filtrar, enriquecer, dividir, unir ou remover dados duplicados.
Os dois métodos mais comuns para esse tipo de tratamento são ETL (Extract, Transform e Load, na sigla em inglês) e ELT (Extract, Load e Transform, na sigla em inglês).
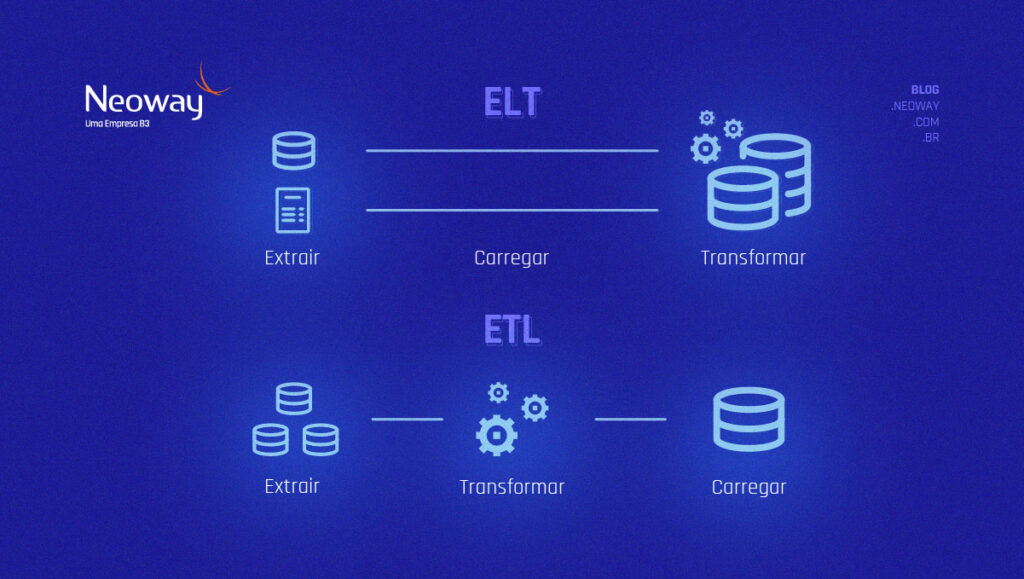
A principal diferença entre esses métodos é a ordem em que você executa as três tarefas descritas nas siglas: extração, transformação e carregamento.
As ferramentas ETL pegam dados de um banco e os colocam em outro após a conversão e inspeção de qualidade. Já o ELT pode ser considerado um “refinamento” da metodologia anterior porque inverte a ordem das etapas de transformação de informações da abordagem tradicional de ETL.
Assim, o processo extrai os dados de um sistema de origem para outro de destino e as informações são transformadas para aplicativos downstream. Ao contrário do ETL, onde a transformação de dados ocorre em uma área de preparação, antes de serem carregados no sistema de destino, o ELT carrega os dados brutos diretamente no sistema de destino e os converte lá. O que faz com que o ELT seja considerado mais otimizado — diminuindo o tempo da transferência de dados.
Tanto ETL quanto ELT são processos usados para obter dados de um local, geralmente bruto, para outro destino, onde os dados são mais refinados após a transformação.
Alguns especialistas descrevem quatro etapas como as principais para transformar dados:
As quatro etapas do data transformation
1) Fornecendo os dados
O primeiro passo é identificar quais são os dados que precisam passar por algum processo de transformação. Lembrando que os conjuntos de informações podem vir de muitos lugares diferentes: sites, softwares, bancos de dados públicos e vários outros.
Essa etapa é vital para que, na sequência, não sejam comparadas “maçãs com laranjas” ou seja, grandezas que não se relacionam. Para esse processo é possível usar uma ferramenta de criação de perfil de dados, como Talend Open Studio e Apache Griffin, dentre outros.
2) Mapeando os dados
Já o mapeamento de dados é o processo criativo de descobrir como conectar dados de dois lugares diferentes, transformando dados de um formato em outro. Vale lembrar que os dados chegam em diferentes tipos de formatos (JSON, texto, booleano, inteiros) e precisam ser analisados adequadamente para se ajustarem ao formato de destino.
A dica aqui é começar descobrindo em que formato seus dados vêm e em qual formato você precisa deles para exibir o resultado. Em seguida, mapeie os campos de origem para os campos de destino e identifique o código necessário para alterar o tipo de dados.
3) Codando as transformações
Agora que os dados foram identificados e suas transformações foram mapeadas, é hora de colocar a mão na massa. Ao descobrir quais transformações podem ser usadas para alcançar a saída desejada, é importante escrever um código que possa fazer a transformação.
Existem ferramentas de apoio nesse processo. Os cientistas de dados podem usar ferramentas como dbt ou Apache Airflow nesse momento. Esse é um dos momentos mais importantes de toda a data transformation porque é onde a maioria dos erros pode ocorrer.
Para evitar que os dados sejam corrompidos por acidente (saiba mais sobre data leakage aqui, por exemplo), você pode usar um conjunto de dados de amostra e executar a transformação nele. Depois de fazer todas as alterações necessárias,é hora do show!
4) Validando os dados
Uma das tarefas menos “glamourosas” do processo de transformação de dados é a etapa de validação. Trocando em miúdos, é hora de garantir que o trabalho feito nas etapas anteriores ficou bem feito.
Para isso, é necessário realizar testes de validação para garantir que tudo funcionou conforme o esperado. Alguns desses testes podem incluir a verificação de exclusividade, a verificação de valores esperados nas colunas e a verificação de contagens e valores agregados.
A dica dos especialistas no assunto é fazer a validação cruzada de dados com o maior número possível de locais para garantir a qualidade e a integridade do resultado final. A transformação de dados pode ser um processo longo e, mesmo que seus dados não tenham erros no início, você pode ter introduzido inconsistências em vários estágios. Validar os dados poupa uma série de dores de cabeça posteriores.
Em resumo, data transformation pode não ser tão chamativo quanto construir modelos de machine learning, usar edge IA ou criar painéis de dados, mas são tão importantes quanto esses outros dois processos. É uma etapa essencial em todas as tarefas analíticas.
Para saber mais sobre os principais indicadores, tecnologias e projetos realizados pelo time da Neoway, confira nossa página de Cases de Sucesso. Além de insights valiosos, o conteúdo indica caminhos para adoção do que há de mais avançado em análise de dados e inteligência artificial para impulsionar seus negócios.